PDF's durchsuchbar machen - mit OCRmyPDF und Automator

KISS - "keep it simple, stupid"
Der Dateityp PDF/A ist perfekt für die Archivierung von Schriftstücken aller Art. Somit gelangt bei mir seit Jahren alle Briefpost zunächst auf den Scanner, der dann brav aus vielen Seiten handliche PDF-Dateien zaubert.
Soweit, so gut. Doch es sei angemerkt, dass es sich hierbei um SCAN's handelt, also nicht um maschinenlesbare und somit auswertbare, durchsuchbare PDF-Dateien. Doch dieses Manko lässt sich dank der Arbeit von OCR-Software schnell und einfach lösen. Genutzt wurde hier das Framework tesseract, welches aber bedauerlicherweise keine PDF-Dateien als Eingaben mag. Somit hat jbarlow83 sich die Mühe gemacht, dies zu verbessern. Und diesmal so, dass PDF-Dateien gelesen werden können, die Texterkennung gestartet wird und anschließend der erkannte Text als durchsichtige Maske über den Scan gelegt wird. Die Dateigröße ändert sich nur minimal, es werden automatisch zukunftssichere PDF/A-Dateien erzeugt und somit eignet sich diese Lösung perfekt für ein Langzeitarchiv.
Die Installation ist dank brew auch denkbar einfach:
# brew install ocrmypdf
Nun kann man testweise einmal eine Datei umwandeln lassen:
# ocrmypdf input.pdf output.pdf -l deu+eng
wandelt das input.pdf nach output.pdf und verwendet für die Texterkennung die Sprachen Deutsch und Englisch.
Je nach Seitenanzahl und CPU-Power dauert dies pro Dokument einige Sekunden.
Hiernach wird man zunächst keinen Unterschied feststellen. Wenn das nun gewonnene Dokument in "Vorschau" öffnet, kann man mit gedrückter Maustaste den Text markieren und per Zwischenablage in ein anderes Dokument übertragen.
PERFEKT - Oder doch noch nicht vollständig?
Nein, nicht ganz. Denn es haben sich um Laufe der Zeit hunderte Dokumente angesammelt. Und zu allem Überfluss wurde hier eine neue Datei erschaffen und die Zeit-/Datumsinformationen der Ursprungsdatei gingen verloren.
Also noch einmal zurück an Reissbrett:

Und nun zeigt sich die Stärke von Mac OS X: mit Automator wird die Sache hier rund, und zwar wirklich einfach.
Automator kennen Sie nicht? Sie arbeiten seit Jahren mit Apple-Rechnern? Gut, die wenigsten kennen die echte Power unter der Haube
Wir klicken auf Launchpad, suchen den grauen Kasten Andere und finden darin Automator

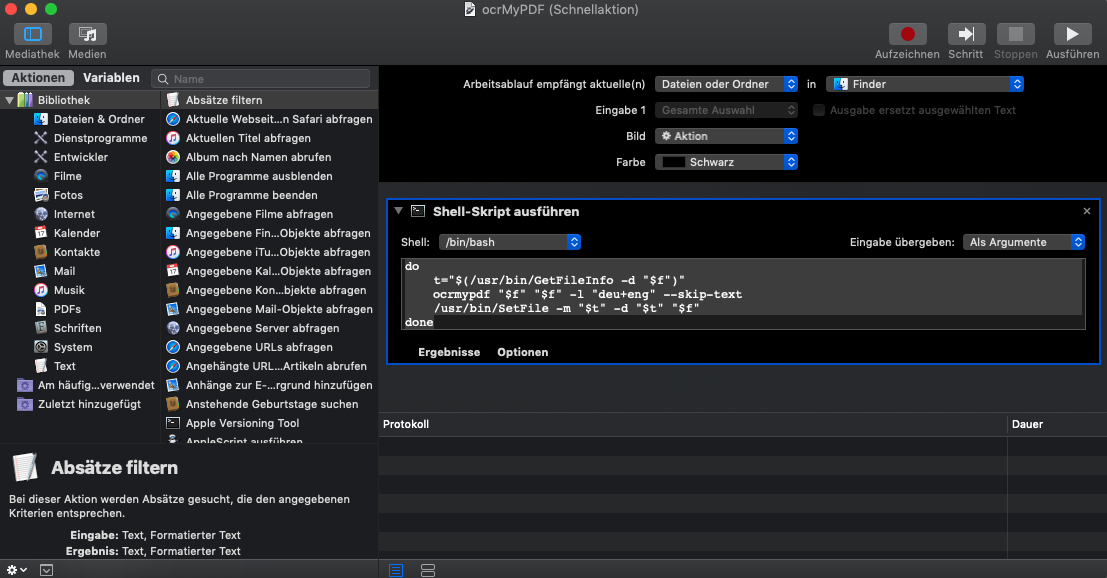
Dort wählen wir links unten Neues Dokument und anschließend Schnellaktion.
In das Suchfeld (Lupe, blinkender Cursor) geben wir shell ein und bestätigen das Ergebnis shell-Skript ausführen mit Enter.
In dem großen grauen Feld geben wir das folgende Script ein:
export PATH=/usr/local/bin:$PATH
for f in "$@"
do
t="$(/usr/bin/GetFileInfo -d "$f")"
ocrmypdf "$f" "$f" -l "deu+eng" --skip-text
/usr/bin/SetFile -m "$t" -d "$t" "$f"
done
Erklärung:
Die erste Zeile Zeile erweitert den Suchpfad für das Programm um den Pfad /usr/local/bin, dann beginnt die Abarbeitung der Dateien:
- Der Timestamp wird in die Variable t gerettet
- Das Script ocrmypdf wird ausgeführt, die Originaldatei hierbei überschrieben. Sollte diese bereits bearbeitet worden sein, sorgt --skip-text dafür, dass keine Fehlermeldung den Vorgang abbricht:
- Die gerettete Zeit-/Datumsinformation wird mit SetFile zurückgesichert.
WICHTIG: Beachten Sie die Groß-/Kleinschreibung in Zeilen 1. und 3.
Die Menüpunkte der Pull-Down-Menüs oben entsprechend einstellen:
Abschließend in Ablage - Sichern noch einen sprechenden Namen eintragen, unter dem das Script zukünftig erreichbar sein soll.
Alle Finder-Fenster nun schließen, Finder öffnen und mit einem Rechtsklick auf dem/den PDF's die Schnellaktion mit dem oben vergebenen Namen auswählen.
Ein sich drehendes Zahnrad ganz oben neben der Uhr/WLAN-Anzeige zeigt an, dass der Automator arbeitet. Etwas Geduld, dann sind auch viele Dateien einfach konvertiert.